

English isn't a programming language (yet)
If English is a programming language, then why isn't your codebase in English?


Code has some magical properties that allow teams of specialists to construct remarkably complex systems with it. Code can be versioned, diffed, refactored, analyzed, and composed. When I was at Google, the company monorepo was over 2 billion lines of code built by tens of thousands of developers. Those properties of code—and the tooling ecosystem around code—are what enabled that massive scale of coordination over nearly three decades. None of those properties belong to natural language prompts.
But natural language has two big advantages over code.
The first advantage is that anyone can use it. With coding agents as natural language translators, designers and product managers are pushing pull requests alongside engineers, informed by their unique perspectives on user needs and business strategy.
Given their new capabilities, teams are seizing this opportunity to unify cross-functional teammates around the codebase. I recently spoke to a team that had onboarded their entire sales team to the company repo armed with Claude Code. Engineers are producing more code than ever and their counterparts are producing code for the first time (Godspeed, Github’s servers).
The second advantage that natural language has over code is its capacity to express the rationale and intent behind programmatic logic.
Peter Naur argued in 1985 that the theory of the program, the distributed understanding of how a system works and why it works that way, is far more valuable than the code itself. Code is a product of the theory, but the theory is what makes a team capable of maintaining, extending, and reasoning about the artifact over time. That theory has always been fragile, because it lived in people’s heads and in documents that went stale the moment someone opened a text editor.
The theory of the program is the new bottleneck in product development. Code is built for logic. English is built for alignment and understanding. The problem is that these two layers—theory and logic—drift apart every time a decision is made, because nothing keeps them in sync.
If you want the team to coordinate around a single artifact, that artifact needs to have the properties that make code reliable (versioned, diffed, composable, current) and the properties that make English useful (legible to anyone, capable of expressing intent and rationale). And those two sets of qualities need to be fused into a unified whole, free of conflicts, that the entire team can align around.
The team can no longer see what they’ve built or why, and situational awareness collapses as velocity peaks.
Our team has begun calling this problem the fog of war. Stack Overflow’s latest developer survey found 69% of developers say agents have boosted their personal productivity. Only 17% say the same about team collaboration. Individuals are faster, but team throughput lags behind.
The fog of war is thicker than it has ever been.
Exclusion, fragmentation, and drift
The shortcomings of code and natural language, paired with the velocity of agents, have created three problems.
First: Exclusion means that only half the team can read the codebase. That project of onboarding the sales team to Github? It was chaos. Salespeople understand customers very well, but they don’t know git. Engineers trying to untangle a salesperson’s (valuable) intent from their vibecoded slop is an expensive waste of their time. Worse still, increasing reliance on agents has introduced cognitive debt among engineers. On many teams now, nobody understands the code.
Second: Fragmentation means that the theory of the program is scattered across Figma, Notion, Linear, and Slack. Even worse, it is now increasingly siphoned off into the ephemeral context windows of local agents, where no teammate can access it at all. David Crawshaw wrote a fantastic blog post observing that code review was never primarily about catching bugs. What it actually accomplished was communicating design changes to other engineers who maintained a mental model of the system. The reasoning that used to survive the game of telephone — handoffs, reviews, shared docs — is now absorbed by agents and discarded at the end of every session.
Third: Drift means that every artifact capturing intent goes stale the moment the next decision is made. Context rot has always been a problem, but increasing code generation velocity decreases the half-life of every spec, PRD, and architecture decision record to near zero. A Mag7 engineer recently estimated that his team spends between 20 - 40% of their time trying to keep these artifacts current or executing against stale specs that someone forgot to update.
Of course, these three forces compound. The mythical man-month has become the mythical agent-month.
The evidence is everywhere. Bugs per developer are up 54% . Incidents per pull request have increased more than 3x. Median PR review time has increased 441%, and 31% more PRs are merging with zero review, because reviewers can’t keep pace. Feature branch activity is up 59% year over year, while main branch throughput fell 7% for the median team. The system is producing more activity and less forward motion.
Some of the authors of the above reports put it well: “a factory that can produce more components than it can assemble does not become more productive. It accumulates inventory.”
Why every current solution fails
The clear impulse is to unify the team around the codebase.
When teams first bring in coding agents, they get flooded with generated code. This is exciting, but quickly becomes unmanageable. Not even the most senior engineer can make sense of the enormous PRs coming their way, so the knee-jerk reaction is to throw more agents at the problem in the form of review agents.
PR review agents can tell you that a function signature is malformed or a dependency is outdated, but they operate at the level of the diff. They cannot tell you whether the feature being built is the right feature. The intent is nowhere to be found.
So teams arrived at a second-order solution: align on specs before anything goes to the agents, so at least everyone knows what’s supposed to be in those PRs.
Spec-driven development is a move in the right direction, but specs alone only work when you understand the problem well enough to write them. The act of building reveals information that the act of specifying cannot anticipate. Even if a spec is implemented faithfully by agents (for which there is limited verification), there’s almost always subsequent changes that introduce drift between spec and code, and the spec goes stale.
The team is left with the same problem, an ongoing struggle to align on and preserve the “theory of the program” they are driving towards. Code is an insufficient surface for shared understanding, and every tool that operates at the level of code inherits that limitation.
The hyperspec
But if English is a programming language, then why aren’t our codebases in English?
If our codebases were English, anyone could read them.
If our codebases were English, the theory of the program could live with the logic of the program, and that theory couldn’t drift from the code.
If our codebases were English, they could still be versioned, diffed, refactored, and composed.
The same agents that thickened the fog have properties that make this future possible. They are universal translators with infinite patience. They can be in every doc, thread, and meeting, ask us questions, and infer our reasoning from qualitative context. Agents can be cognitive infrastructure for coordination, a sync engine for humans.
Ted Nelson coined the term “hypertext” to describe text that broke out of linear constraint, text that could reference, branch, and stay live against a moving body of other text. Hypertext was text with a different topology. What the era of agentic engineering needs is hypertext for the theory of the program. One possibility is what we call hyperspecs.
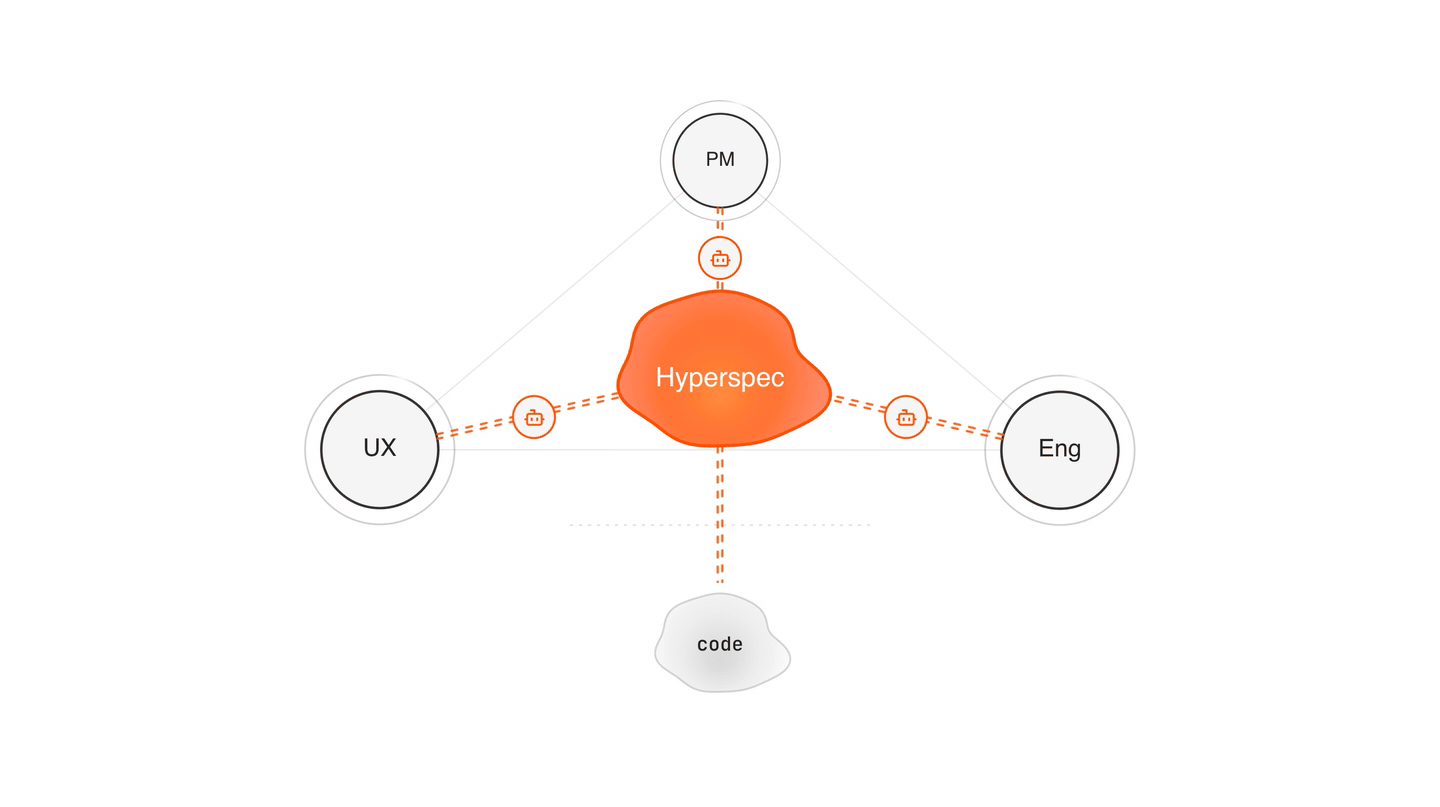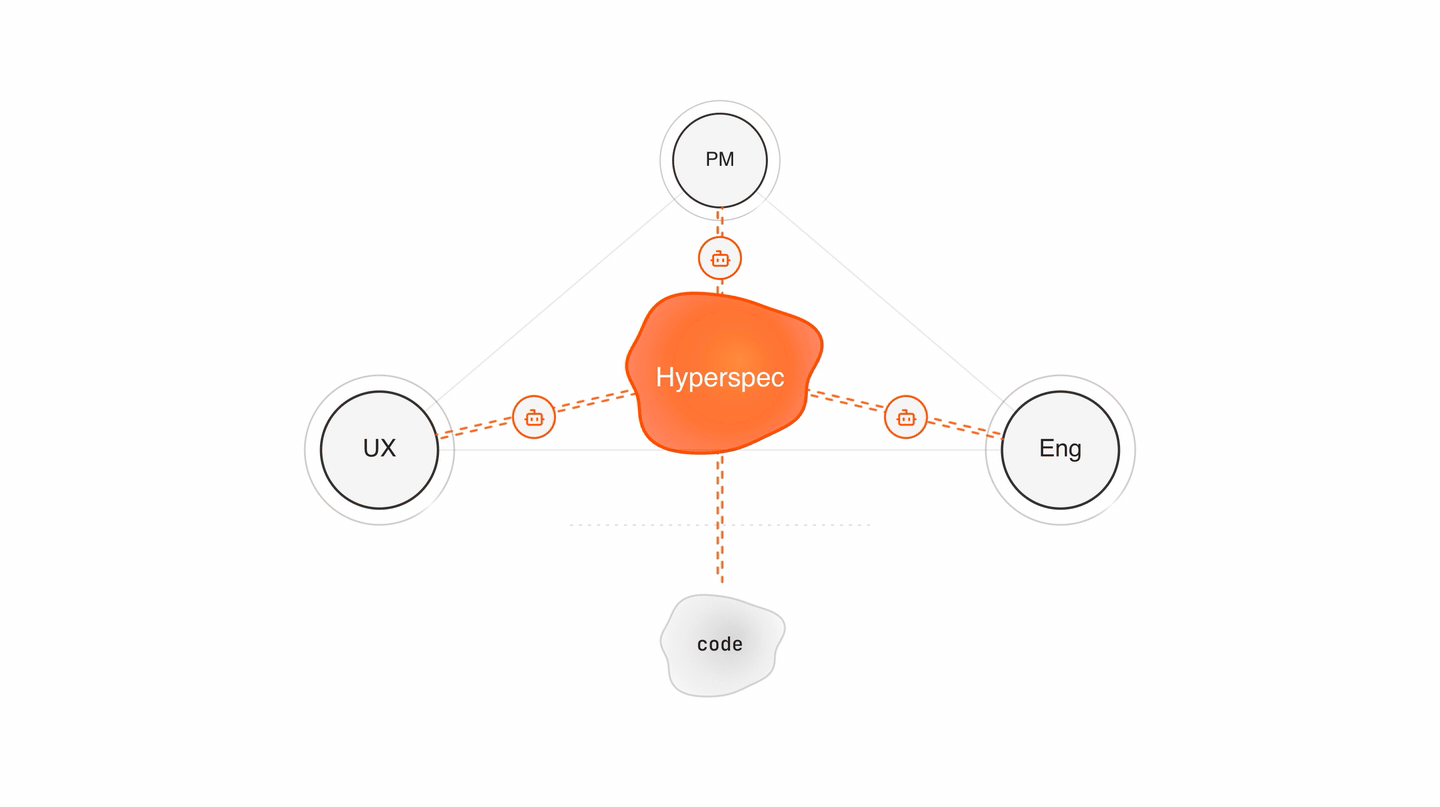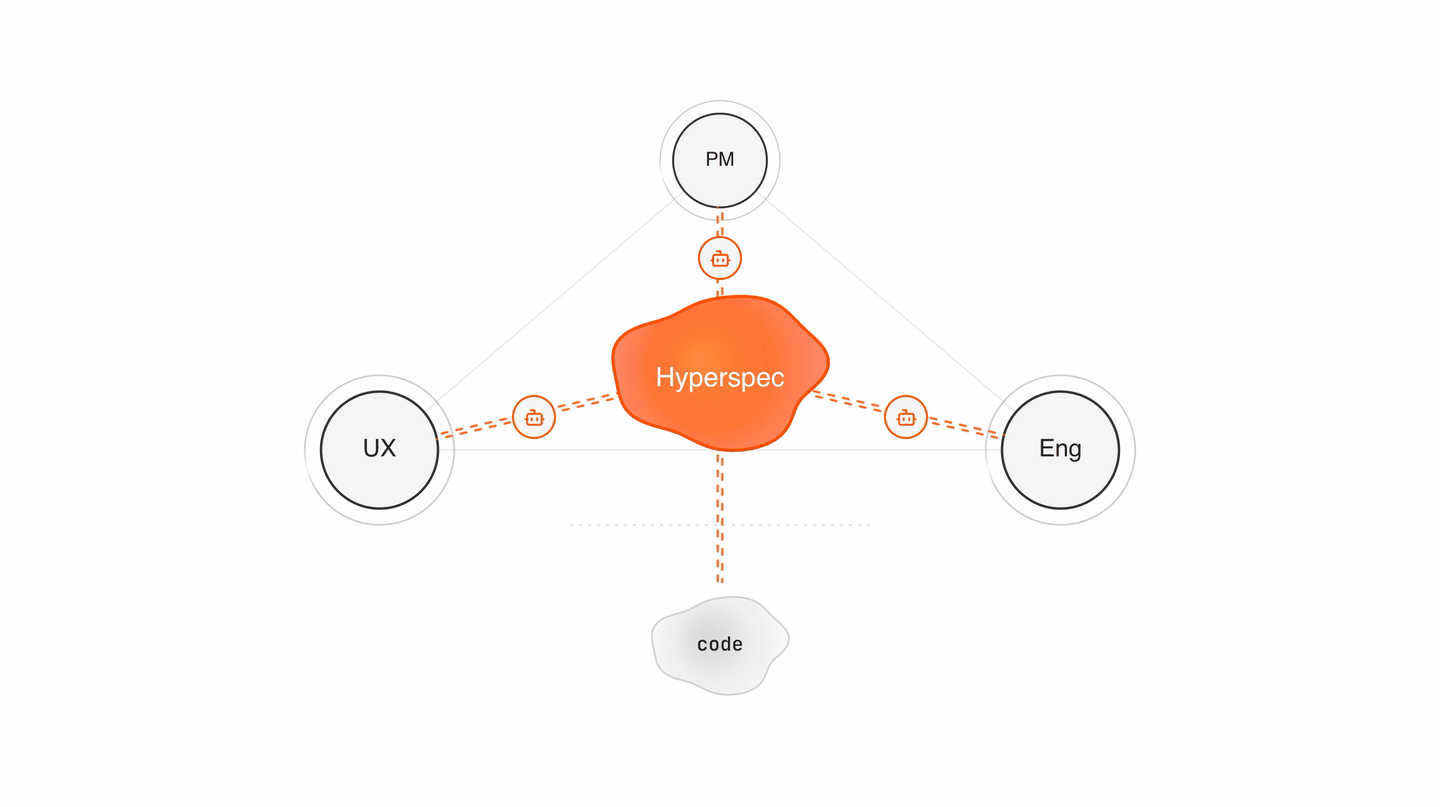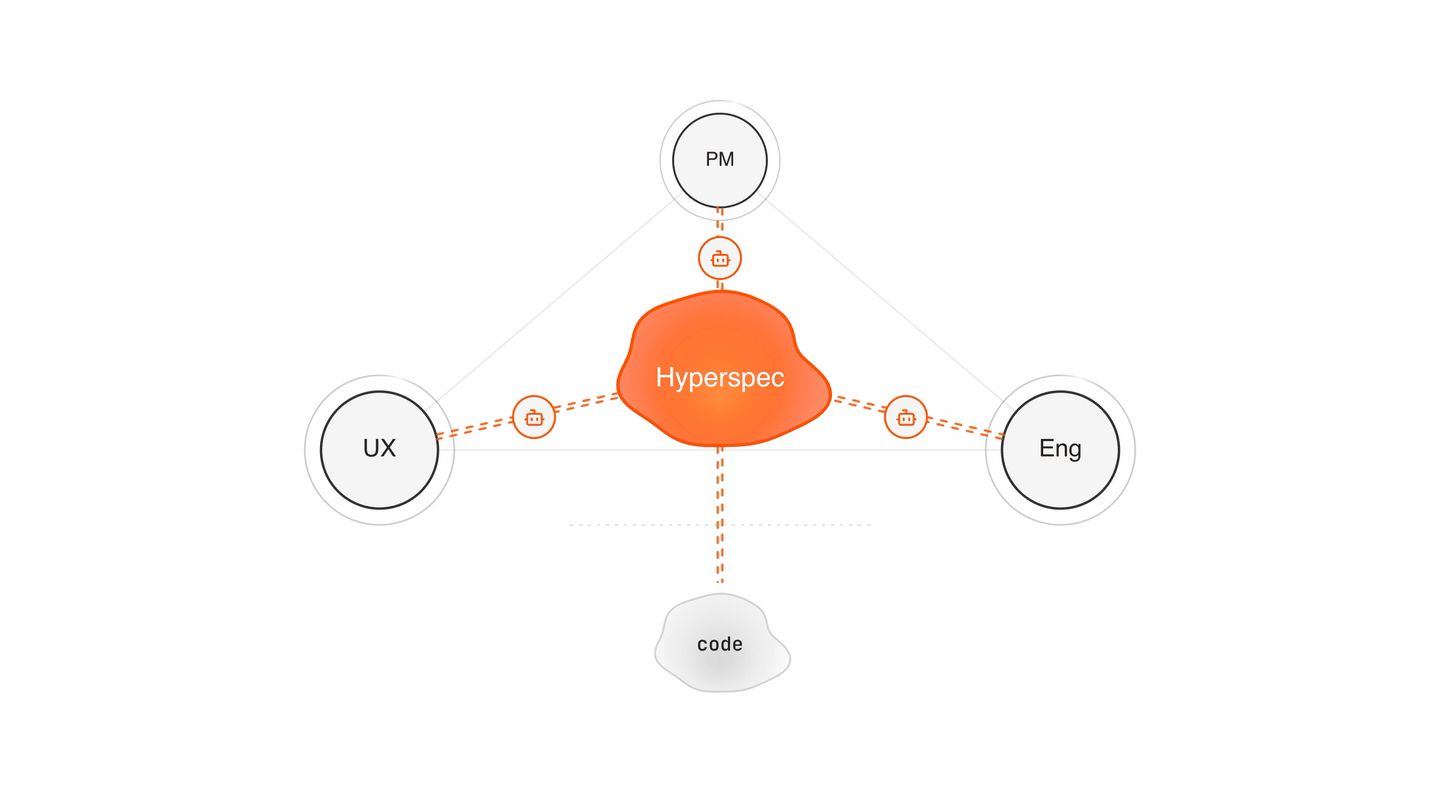
A hyperspec is both intent and self-updating documentation, written in English, that captures what a product is, why it was built that way, and the relationships between those decisions. It’s the product of infrastructure that proactively maintains the theory of the program for both humans and agents alike.
The key property of a hyperspec is that it stays in complete sync with the codebase at all times. Agents-as-infrastructure maintain the semantic mapping and verification layer that makes this possible. This background process turns the hyperspec into a durable natural language abstraction layer: the codebase in English.
The hyperspec is the translation between theory and code. When upstream assumptions change, the system knows which downstream decisions are affected, and the theory of the program stays current.
Where traditional specs ask you to simulate possibilities upfront, hyperspecs can be generated from working sessions with agents that let you explore a design space without worrying about code. Production-grade architecture can be handled separately in the hyperspec by the appropriate teammate.
The hyperspec creates a shared surface for each team member to leverage their unique skillset and address their relevant concerns. Further, their decisions are visible and legible to other teammates and their agents as a byproduct of work.
A PM can chat with an agent that references both the sales team’s customer calls and the codebase, exploring opportunities in the adjacent possible and ensuring no collisions with in-flight workstreams to generate a PRD-like hyperspec. A designer can prototype the idea with Claude Code and the system passively integrates their design decisions and rationale back into the same hyperspec (along with the prototype). An engineer can use this comprehensive corpus of intent to contribute the appropriate architecture for scale, security, and reliability to the same hyperspec. Agents translate it into tests and code. Everyone has situational awareness of cross-functional decisions made in real-time, lifting the fog.
Three months from now, any team member or agent can read, in plain English, why a particular API endpoint exists, what user problem it solves, which design decisions constrain its behavior, and how it relates to the three features that depend on it. The codebase becomes more coherent as it’s built, and the team gets collectively smarter about its own product over time.
The hyperspec is your product described in a language everyone on the team can read.
English should be a programming language
English should be a programming language. If an agent can turn a sentence into a feature, the sentence is the more durable artifact. The code is compiled output. The hyperspec stays alive and connected to the system it describes.
The theory of the program is the bottleneck now. Every team we talk to is producing more code and understanding less of it. The tools that promised to fix this still operate at the level of code.
Software is the substrate of every consequential decision now—what gets built, who it serves, what it does to them. Teams that hold their theory of the program together will shape the next decade. The ones that don’t will keep shipping software they can’t explain to themselves.
We’re building the decision infrastructure that makes hyperspecs possible at Primitive. For early access, sign up at getprimitive.ai. If you’d like to help us build it, reach out: kasey@getprimitive.ai
The third major thing natural language has that is different from code is load-bearing ambiguity from context, often the context of social hierarchy. E.g. "lovely store you have here, would be terrible if something bad were to happen to it", or, "want to come over and watch netflix?"
I worry this will be game breaking. People expect to use natural language with social ambiguity, computers mostly don't.
More in this talk: https://www.youtube.com/watch?v=LjQM8PzCEY0